# Kolumny kategoryzujące
Schematy analiz statystycznych oraz budowa problemów badawczych wymagają niejednokrotnie podzielenia całej próby na pewne podgrupy. Najprostszym przykładem jest tworzenie grupy badawczej i grupy kontrolnej. Niektóre zmienne mogą definiować grupowanie bez żadnej interwencji użytkownika, jak np. płeć pacjenta czy rozpoznanie (gdy podczas definiowania scenariusza użytkownik podał dwa możliwe rozpoznania). W wielu sytuacjach definicja grup nie jest jednak tak bezobsługowa. Podstawowym problemem jest mnogość kodów rozpoznań i nazw handlowych leków. Możemy sobie wyobrazić następujące sytuacje - chcemy porównać w badaniu kobiety, które rodziły siłami natury oraz kobiety, u których wykonano cesarskie cięcie. Nazwa procedury nie może tu stanowić zmiennej grupującej, ponieważ cesarskie cięcie może być zakodowane jedną z dziewięciu różnych nazw:
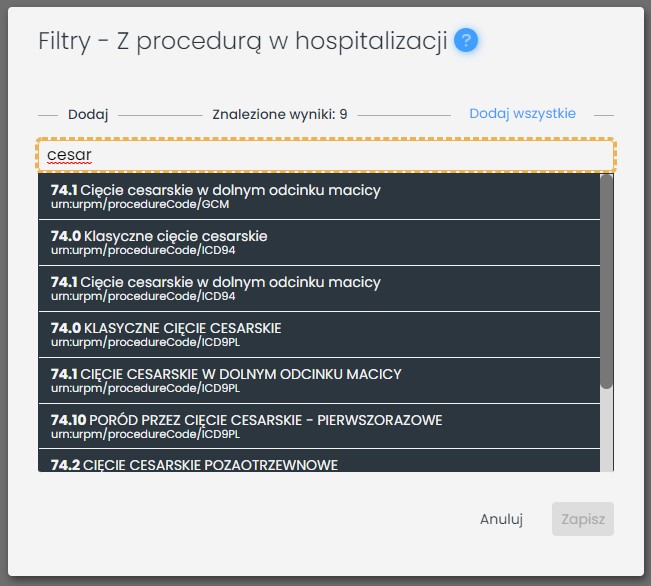
a poród drogą pochwową - jedną z trzynastu nazw:
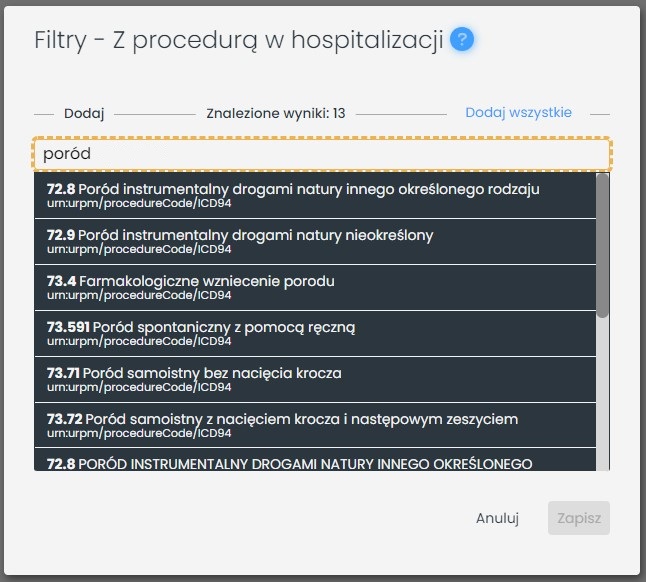
Zmienna „Procedura" ma więc 22 wartości, które merytorycznie wydzielają jednak dwie grupy. Podobna sytuacja może wystąpić w kwestii podanych leków - chcąc porównać działanie dwóch leków, użytkownik może podać kilkanaście nazw handlowych dla każdego z nich, dlatego zmienna „Nazwa handlowa" nie będzie w stanie wydzielić dwóch grup.
Aby rozwiązać ten problem, system został wyposażony w opcję tworzenia zmiennej kategoryzującej. Jako przykład zastosujemy przytoczony wyżej przykład z porodem i cesarskim cięciem. Na początek należy wytworzyć scenariusz, na podstawie którego otrzymamy pacjentów o oczekiwanych cechach (czyli nałożyć wszystkie zaplanowane filtry). W naszym przykładzie oznacza to wytworzenie kroku pierwszego w kontekście „Pacjent" z filtrem „Z wykonaną procedurą" oraz dodanie wszystkich procedur wyświetlających się na liście podpowiedzi po wpisaniu „cesar" oraz „poród". W ten sposób otrzymamy grupę kobiet, które mają w swojej historii co najmniej jeden poród. Może się więc okazać, że w grupie znajdują się kobiety, które przebyły zarówno poród, jak i cesarskie cięcie. Należy się więc zastanowić, w jaki sposób chcemy definiować grupy. Załóżmy więc, że będą nas interesowały tylko te kobiety, które rodziły tylko jeden raz. Aby uzyskać taką grupę, w drugim kroku należy wybrać pozycję „Procedura" i odfiltrować tylko te kobiety, które procedurę porodu lub cesarskiego cięcia przeszły tylko jeden raz. Ponieważ posiadamy już finalną próbę pacjentów, możemy stworzyć zmienną kategoryzującą.
Schemat postępowania jest następujący: należy wykonać w scenariuszu kolejny krok i wybrać pozycję, który ma rozdzielać próbę wynikową na podgrupy (czyli w naszym przypadku „Procedury"), wybrać filtry, które mają określać jedną z grup (czyli np. nazwy procedur „cesarskie cięcie") oraz wybrać opcję „Minimalna liczba wyników" większa lub równa 0. Przy takim ustawieniu żadna pacjentka nie zostanie odfiltrowana, zobaczymy za to, że pod przyciskiem „Minimalna liczba wyników" pojawiły się trzy małe ikonki z cyframi 1, 2 i 3. Wybieramy przycisk „1" i nadajemy nazwę kategorii (czyli „Cesarskie cięcie"). Wszystkie rekordy, które spełniają warunki zdefiniowane na tym kafelku, otrzymają w kolumnie kategoryzującej wartość „Cesarskie cięcie (+)". Definiowanie drugiej kategorii („Poród naturalny") nie jest konieczne, ponieważ dopełnienie kategorii pierwszej zostało oznaczone jako „Cesarskie cięcie (-)".
Po zapisaniu kroku i otrzymaniu wyników wyszukiwania należy uruchomić podgląd tabeli wynikowej i na liście po lewej stronie ekranu włączyć kolumnę „Kategoria 1" znajdującą się w sekcji „Krok nr 1".
Cyfry „2" i „3" służą do ustalenia ewentualnych kolejnych kolumn kategoryzujących, dotyczących innych cech pacjentów, np. podanych leków lub wykonanych badań. Możliwe jest więc utworzenie maksymalnie trzech różnych kolumn kategoryzujących.